Online data collection with special populations over the World Wide Web
The quick ascendance of the World Wide Web as the dominant vehicle for Internet communication has recently made experimentation in a multimedia environment feasible on the Internet. Although web sites containing online psychology demonstrations and experiments for non-handicapped individuals have appeared in recent years (especially in the areas of cognitive and social psychology), there appear to have been few attempts to conduct online experimentation with special populations. We recently completed two online pilot studies of families with Down syndrome or Williams syndrome members: a) A survey that asks (via Likert rating scales, adjective checklists, multiple-choice style questions, and text-entry boxes) about family background, computer use, and temperament of the special needs family member; and b) An experiment (completed by an individual with special needs) that includes auditory and visual digit span tasks and a memory-for-orientation task in which responses are entered via mouse clicks. Recruiting began with e-mail announcements to representative Down syndrome and Williams syndrome discussion groups, listserves, and bulletin boards, and submission of the project's URL (https://www.cofc.edu/~marcellm/testaw.htm) and key indexing terms to selected search engines. This paper reviews technical aspects of developing the online programs as well as the strengths and weaknesses of online vs. traditional laboratory-based research in relation to issues such as experimental control, delivery of instructions, experimenter bias, participant recruitment, sample heterogeneity, generalization, attrition, privacy, financial costs, data integrity, and ethics. We conclude by offering our thoughts on two ways of implementing online experimentation with special populations: a) Using a remote parent 'helper' as a proxy to work with the target individual; and b) Collaborating with professional colleagues in Web-based projects conducted in traditional laboratory settings.
Marcell, M, and Falls, A. (2001) Online data collection with special populations over the World Wide Web. Down Syndrome Research and Practice, 7(3), 106-123. doi:10.3104/reports.120
Introduction
As Krantz and Dalal (2000) noted, technological advances have a history of stimulating methodological and theoretical advances in psychology; consider, for instance, the relationship between Skinner's operant conditioning chamber and schedules of reinforcement, electronic communications and signal detection theory, microelectrodes and feature detectors in the visual cortex, computers and information processing models of memory, and telephones and modern survey techniques. The theme of this paper is that a recent technological advance - the development of the World Wide Web ("the Web") - may have similar transforming effects on the way we gather empirical data in behavioral research.
Ancient history
It may be useful to begin with technology recollections from the first author's research journey. As an undergraduate student in the late 1960s and early 1970s I collected data with the standard lab apparatus of the time, such as Skinner boxes, mirror star-tracers, telegraph-style reaction time keys, and paper-and-pencil surveys. During graduate school in the mid-to-late 1970s I conducted research in cognitive and developmental psychology either by creating my own equipment (e.g. a lever-movement apparatus) and stimuli (e.g. plastic-sheathed flash cards) or by using standard equipment like stopwatches, slide projectors, and tape recorders. My primary contact with computers consisted of frequent visits to a large, cold, forbidding, glass-encased room containing an IBM mainframe computer. The ritual required that I hand a box of keypunched computer cards to a pale technician and return a few hours later to receive a printout of a factorial ANOVA that did not run because of a hard-to-detect keypunch error. A graduate school advisor expanded my introduction to computers by showing me how to collect heart rate data from infants using the latest Hewlett-Packard minicomputer (there is still a box of punched paper tapes in my attic - it has been almost two decades since I have had access to a teletype machine that can read the tapes). In the late 1970s and early 1980s, when I became a faculty member, I expanded my technology horizons by creating low-budget video-tapes that could be shown in the field to elementary students over my newfangled portable VCR and portable TV. It was during this period that I also began to play with personal computers (initially Wang, later IBM), largely for the purposes of word processing.
Then something happened in the 1980s - personal computing took off. The personal computer rapidly became the primary research tool in cognitive psychology laboratories, replacing such time-honoured apparatus as the tachistoscope, memory drum, and reaction timer. By the late 1980s I was a complete computer convert, an investigator who used Animated Voice software to create auditory stimuli, photo editing and paint programs to create visual stimuli, and Micro Experimental Laboratory to produce refined computer-based experiments. There has been no looking back - the personal computer is now the indispensable, ubiquitous workhorse of every human behavior laboratory. Its versatility is astonishing: it is used to present stimuli, measure responses, randomize items, record and analyze data, create reports, generate tables and figures - the list goes on and on.
During this time the computer not only became a well-honed tachistoscope, but also began to evolve into something that may prove even more revolutionary in the long run: a vehicle for instant communication and worldwide exchange of data. Personal computers became linked to other computers over the Internet. E-mail and electronic file transfer, which permitted long-distance collaboration and rapid sharing of information, altered the face of academic research and teaching. Researchers became able, for the first time, to gather data from text-based online archives and to collect responses from electronically-distributed email surveys.
It is this kind of interconnectedness that led Musch and Reips (2000) to state that 20 years after the establishment of the laboratory computer as the primary research tool, another dramatic change is afoot - the explosion of the Internet and the linking of individuals in a network of interactive communication. They and others have observed that the key factor in the tremendous expansion in Internet use was the development of the World Wide Web. The Web, coupled with the development of HTML, easy-to-use browsers like Netscape, and new languages like Java, exploded in popularity in the mid-1990s because of an exciting dimension it added to computing: the possibility of real-time, dynamic interactions between users. Largely because of the Web's easy-to-use graphical interface, multimedia environment, intelligent search engines, and interconnectedness through links to millions of web pages across the world, there is now an exponentially growing community of users [estimated at 375 million at year-end 2000 by CyberAtlas ( https://cyberatlas.internet.com/ )] who are becoming increasingly representative of society as a whole. It is safe to assume that the size of this community will continue to grow as computers and connections become faster and cheaper.
Emergence of a new research approach
Here's the part that should be interesting to behavioral researchers: The late 1990s saw, for the first time, postings of experiments on the Web for the purpose of research. As Smith and Leigh (1997) noted, "Almost any experiment capable of running on a desktop computer can be run from a remote site," (p. 504). This is absolutely true for text-based studies, and is becoming increasingly true for studies involving pictures, sounds, animation, and video.
What kinds of studies are being posted? In a recent survey of 29 researchers who have conducted online experiments, Musch and Reips (2000) found the following:
- Experiments were typically in the field of cognitive psychology, focusing on topics in areas such as thinking and reasoning, psycholinguistics, sensation/perception, memory, and decision making.
- Experiments were primarily offered in English and German.
- The mean number of participants in a study was 427 (the range was 13 - 2,649).
- 66% of the participants who started an experiment finished it.
- No researcher observed evidence of a hacker attack.
- 46% of the experiments used graphics, 6% used sound, and 23% measured reaction time.
- The average duration of an experiment was 22 minutes (the range was 5 - 90 minutes).
- 27% of the experiments offered individualized feedback and 9% offered monetary rewards.
- Over half of the experimenters conducted replication studies in traditional settings, and almost all of these noted close agreement between lab and online data.
Various landmarks in the emergence of online experimentation (as opposed to e-mail surveying, which predates the establishment of the Web) are actually quite recent. According to Musch and Reips' (2000) excellent overview of the history of online experimentation, the first online source of true psychology experiments was established in September, 1995, by Ulf-Dietrich Reips. The "Web's Experimental Psychology Lab," originally at the University of Tübingen, and now at the University of Zürich, is still active today and includes experiments in German and English. The first online experiment published in a psychology journal was by Krantz, Ballard, and Scher (1997), who reported a close correspondence between the patterns of results obtained in laboratory and online studies of the determinants of female attractiveness. The most comprehensive, up-to-date source of information about online experimentation is the book, Psychological Experiments on the Internet, edited by Birnbaum (2000a), a very useful resource for anyone wishing to learn about this new way of conducting research.
Psychologists are thus in the earliest stages of conducting Web-based research. Current efforts in online experimentation vary widely in their sophistication and employ different technologies, informed consent procedures, and so on. Perhaps the best way to "get a feel" for online experimentation is to participate in online experiments. Table 1 contains a list of links to several Web-based experimentation sites.
| American Psychological Society: Psychological Research on the Net | https://psych.hanover.edu/APS/ exponnet.html |
| Coglab: Cognitive Psychology Online Lab | https://coglab.wadsworth.com/ [was https://coglab.psych.purdue.edu/coglab/] |
| PsychExperiments: Psychology Experiments on the Internet | https://psychexps.olemiss.edu/ |
| Yahoo! Listing of Tests and Experiments in Psychology | https://dir.yahoo.com/Social_Science/ Psychology/Research/Tests_and_Experiments/ |
| Web's Experimental Psychology Lab | https://www.psych.unizh.ch/genpsy/ Ulf/Lab/WebExpPsyLab.html |
Online study of special populations
Why study special populations online?
One aspect of the Web that should be attractive to researchers is its very large number of special-interest groups- people who, for whatever reason, want to be plugged in to the latest information about their topic of interest. There are, for instance, hundreds of web sites around the world dedicated to the topic of Down syndrome. Such sites present an exciting opportunity to the Web researcher- the opportunity to target geographically-remote, specific populations for participation in research.
Web researchers believe that targeted, online recruiting is a practical and promising way to study unique individuals who are difficult to find in sufficient numbers in one's limited geographic region (Reips, 2000; Smith & Leigh, 1997). The Web, through its many special-interest groups, provides an efficient and inexpensive way to reach participants. Anecdotal evidence suggests that the kinds of people who regularly visit special interest sites are indeed people with a personal, vested interest in the topic- parents of children with fragile-X syndrome, relatives of people with closed-head injuries, individuals with obsessive-compulsive disorder, and so on. The Web presents a vehicle for recruiting these individuals and involving them in research. Part of my interest in online research was stimulated by the ever-present problem of too-small samples in both my cognitive psychology laboratory class (especially when the participant pool "dries up" near the end of each semester) and my research with special populations. I have often wondered whether the effects reported in my studies of Down syndrome individuals might generalise to only the limited population of 60 or so Charleston-area families that I have used and reused in research.
During a 1999 sabbatical I began looking for a flexible, user-friendly programming language capable of delivering Web-based content. I decided to learn Macromedia Authorware Attain 5, described in the manual as "the leading visual rich-media authoring tool for creating web and online learning," (Macromedia, 1998, p.1). What we found in Authorware was a program that had a familiar word-processing/paint-like interface and several years of development behind it. Its changes appeared to be evolutionary, and it was friendly enough not to scare us away. Most importantly, there was an interesting online site - PsychExperiments - that had selected Authorware as its development tool. Luckily, the PsychExperiments site was also offering free summer training in the use of Authorware, as well as an experiment template that could be used to build research projects. McGraw, Tew, and Williams (2000), creators of the PsychExperiments site, noted that,
"The primary Authorware audience has been corporations wanting to build Web and CD-ROM-delivered training programs and tests. Nonetheless, Authorware's generic functions are easily adapted to the needs of psychologists who want to present multimedia stimulus events with precise control over timing, permit users to interact with screen objects, and measure users' responses with accuracy on the order of milliseconds," (p. 222).
Psychological hurdles
My apprehensions about beginning an online research project included all of the usual suspects: Sloth (investing large amounts of time learning something that may not yield dividends), fear (re-entering the world of programming at a time when I was becoming eligible for membership in the American Association of Retired Persons), and embarrassment (asking others for help, and then having to wait for their help). Keep in mind when entering the world of online computing that your campus or your medical center is likely to contain several people who can assist you in assembling the various components of an online project. There are individuals who know how to create web pages, student programrs who may want to try their hand at writing an experiment, and a handful of people (those who run the servers) who can create the specialized script needed to get data in and out of a server.
On a personal note, my biggest hurdle was simply carving out the chunks of time needed to learn a new software package. It takes time to learn a new skill, and this is just as true for Authorware as for any software package. All in all, the two studies described in this paper - a survey and an experiment - took about 5 months to develop and test. This relatively fast development time was facilitated by attending the PsychExperiments 3-day summer workshop, using the PsychExperiments template (with its excellent built-in routines), and mining the Aware technical support archive for Authorware professionals ( https://listserv.cc.kuleuven.ac.be/archives/aware.html ). Now that the initial learning time has been invested, I have found a number of uses for Authorware in my laboratory teaching as well as my research.
Technical issues
An early, important decision concerned the distribution of the online studies. One way to distribute programs is to post them on a web page and invite users to download the programs and run them at their convenience. Such programs are executable (.exe) files packaged with a "run-time player." However, we decided against this method of distribution primarily because of the lack of control one has over the materials. Once distributed, .exe files can be altered and redistributed; also, if a serious bug or error emerges that requires immediate attention, there is no way to track down the users. Another reason we decided against .exe distribution is that we did not want to know the identities of the participants. After running an .exe program, data would have been returned by non -anonymous email or FTP, the latter of which would require a login to our server.
We decided, instead, on another distribution approach - "shocking" the files (i.e. packaging them for use over the Web in a browser). This Macromedia technology was originally known as Shockwave, but is now known as Web Packager. A web-packaged program is divided into various segment files and a master map file which are accessed when a user clicks on the hyperlink embedded in the Web page from which the program is launched. Our own shocked online survey and experiment is downloaded from the College of Charleston's server and run in the user's browser. Because the entire study is fully downloaded before the participant is allowed to begin, there are no fluctuations in performance due to back-and-forth Internet traffic. The only communication with the server is in the beginning, when the piece is loaded, and at the end, when the data are sent. This is what Morrow and McKee (1998) refer to as a "client-side script": The user downloads the program to the browser, the program builds completely on the user's computer, and results are relayed back to the server when the user is finished. Although Authorware allows "streaming" of the program in segments, with the user working on sections of the program while the next parts are downloaded in the background, this could affect timing characteristics and is thus not advisable for experiments in which timing is important for stimulus presentation or response measurement ( McGraw et al., 2000 ). In general, posting a shocked file on the Web gives one complete control over a program's content, the capability to make changes when needed, and the reward of immediate, real-time feedback as participants transfer data to the server.
The shocked distribution approach, however, has an important downside - the need to download a sizable Macromedia plugin for one's browser. Although some users already have the plugin loaded into their Netscape or Internet Explorer browser, most do not. The plugin is obtainable from the Macromedia website at no cost, but that is not the issue. Some participants will simply not want to use up more of their hard drive space and others will not want to put up with the long download time. With my new home computer and fast cable Internet connection, the plugin download took only about 1 minute, but with my old computer and its slow dialup modem, the download took 26 minutes! It is a highly motivated participant who is willing to endure such a hefty, slow download; consequently, it may be the case that online samples tested with this technology will prove to be biased towards power-users with more expensive computers and connections.
A hidden counter placed on our project's web page suggested that about 40% of the visitors to our site left before participating in a study. Our hunch is that a significant impediment to participation was their unwillingness to download and install a sizable browser plugin. The good news, however, is that the Macromedia browser plugin needs to be downloaded only once because subsequent Authorware experiments will automatically detect and use the plugin. Future investigators using the shocked approach to distributing studies on the Web might want to explore the use of a minimal Authorware plugin that is about one-quarter as large as the full plugin (the minimal plugin can be configured to include only those components that are needed for a particular study).
There is an important technical piece of the online research puzzle - the CGI (Computer Gateway Interface) part - that we were unable to complete by ourselves. CGI languages are used by servers, the machines that run networks and web pages for universities, companies, and so on. CGI acts like a middleman, transferring data from the user to the server, and putting the data in a place and a form that the researcher can access. Servers differ and so do the CGI languages they use, languages with names like ASP, Perl, and Cold Fusion. We learned from our Webmaster that the College's server was a Unix running Perl. He graciously agreed to write the CGI script for us, and within a few hours had adapted a Perl freeware form mailer script that did everything we needed. 1
Briefly, here is how the CGI portion of our online project worked. When the participant pressed the Send button at the end of the survey or experiment, Authorware passed the participant's data to a CGI script residing in a folder on the server. Authorware transferred the data via a built-in function known as PostURL, a process that is transparent to the user and that occurred in our studies while the participant read the debriefing page. The CGI script parsed the data and did two things: a) It sent an anonymous email message containing the data to the researcher; and b) It added the data to a centrally-stored text file. 2 Anyone considering online research should look into using this kind of collection system - it works beautifully, and you should have no difficulty getting the necessary permission to conduct a study over the server. Your Webmaster will address any security issues.
Development guidelines
It is very important to motivate individuals to participate in your study, and it is equally important to keep their motivation high enough to complete it. A study should therefore be easy to download, at least mildly interesting, have crystal-clear instructions, not have an inordinate number of trials, display some variation during trials to prevent boredom, and have some sort of payoff (if not a monetary reward or amusing reinforcers, then at least an educational component in the debriefing). As Schmidt (1997) noted, dynamic feedback (created by comparing an individual's results with those of individuals who have already run the task) is also highly motivating. If participants know that personalized performance information will be provided, then they might be more motivated to participate, to give more careful responses, and to complete the study.
Common features in our online studies
Our online survey and experiment for individuals with Down syndrome and Williams syndrome shared several features, some of which will be illustrated with screen shots from the experiment. The initial web launch page for the studies contained an overview of the tasks, an automatic procedure that tested the user's computer for the presence of the needed plugin, and directions on how to obtain the plugin. Following the PsychExperiments template, we began the study with a title page, followed by a consent form (see Figure 1). After agreeing to participate, the helper signed on using the first name of the special needs individual (a random 4-digit number was appended to this name to create a unique user ID for the database). Instructions (see Figure 2) and reminders (see Figure 3) were presented throughout the program. Data were held in the temporary memory of the participant's computer while the individual participated in the study. After all tasks were completed, the participant decided whether to send the data to the server (see Figure 4). Regardless of the decision, the participant next viewed a screen of data gathered during the session (see Figure 5), read a debriefing form (see Figure 6), and exited from a thank-you web page that participants were encouraged to bookmark for later viewing of a summary of the findings.

Figure 1. Consent form for online experiment
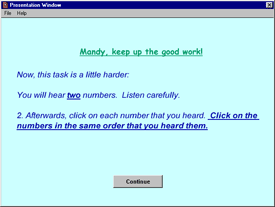
Figure 2. Example of instructions for online experiment
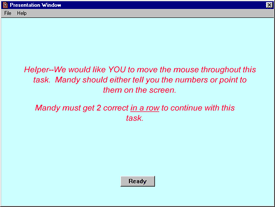
Figure 3. Example of reminder to helper during online experiment
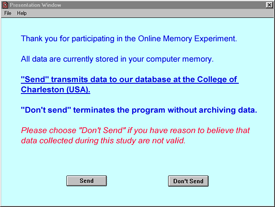
Figure 4. Data transfer entry screen for online experiment
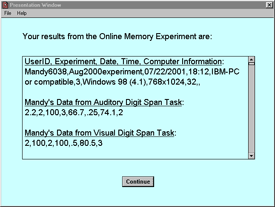
Figure 5. Individual results for online experiment participant
Figure 6. Debriefing form for online experiment
Throughout the remainder of this manuscript we will provide examples of findings from our online pilot studies. The findings are considered tentative and preliminary because the studies were advertised and monitored for only four weeks and attracted a mere handful of participants. The survey was completed by 21 adult helpers (17 with a child with Down syndrome and 4 with a child with Williams syndrome) and the experiment was completed by 5 individuals with Down syndrome, with the assistance of adult helpers. The gender distribution of the combined Down syndrome and Williams syndrome participants was 57% male and 43% female, and their average age was 11.8 years. All lived at home with their families.
Brief description of the online survey
There is a considerable literature on the parent-reported temperament of individuals with Down syndrome and Williams syndrome. In our survey we basically hoped to learn whether online temperament ratings parallel those reported in the literature. Previously-published temperament findings constitute what Mueller, Jacobsen, and Schwarzer (2000) refer to as 'marker patterns,' well-established results that form a basis for comparison.
How to create an online study
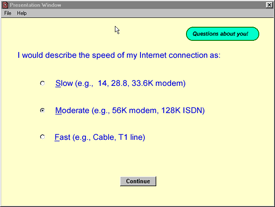
The online survey contained clusters of text items about the participant's demographic background (7 items on sex, age, etc.), the participant's temperament (17 items on anxiety level, degree of extraversion, etc.), the helper's (parent's) demographic background (8 items on income level, educational level, etc.), and the current testing environment (6 items on the number of distractions, type of computer, etc.). The four clusters of items were presented in a random order, and the items within each cluster were also presented randomly. Different types of items were used, such as Likert rating scales (see Figure 7), adjective checklists (see Figure 8), and multiple-choice questions (see Figure 9). Data were gathered on 50 variables, and there was randomization of items at all levels of the survey. The mean time needed to complete the survey was 7 minutes, 36 seconds.
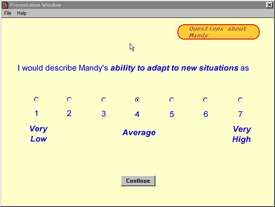
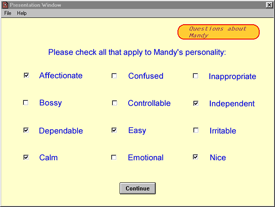
Figure 8. Example of adjective checklist from online survey
Acknowledging the limitations of such small samples, it is nevertheless interesting to note that most of the temperamental differences between Down syndrome and Williams syndrome samples were in the predicted direction. Parents of children with Williams syndrome tended to rate their child as more restless, afraid, anxious, emotional, irritable, confused, inappropriate, uncooperative, likely to cry, and overly friendly; and less attentive, adaptable, calm, independent, and reserved, than parents of children with Down syndrome, as found in previous research studies (e.g., Gosch & Pankau, 1997; Jones, Bellugi, Lai, Chiles, Reilly, Lincoln, & Adolphs, 2000 ; van Lieshout, DeMeyer, Curfs, & Fryns, 1998; Morris & Mervis, 1999). Also, as expected, both groups described their children as affectionate, smiley, sociable, and agreeable, and few parents described their children with Down syndrome as irritable, inappropriate, confused, nervous, or withdrawn.
Brief description of the online experiment
Previous research has reported no difference between auditory and visual memory span scores in the population with Down syndrome in contrast to a pattern favouring auditory over visual span in non-handicapped and other mentally handicapped populations (e.g. Marcell & Armstrong, 1982; Marcell & Weeks, 1988). Our online experiment included auditory and visual digit span tasks in an attempt to conceptually replicate Down syndrome short-term memory marker patterns. Although we have found no reports of auditory and visual digit span tasks used with individuals with Williams syndrome, our reading of the literature suggests that the 'normal' pattern of better auditory than visual memory performance is likely in this population (e.g. Klein & Mervis, 1999).
Following practice trials, the participant was presented digit sequences of increasing length at the rate of one digit every 1.15 seconds (see Figure 10 for an example of a 2-digit visual sequence). The adult helper conveyed the participant's choices with mouse clicks (see Figure 11). Testing was terminated when both trials of a given sequence length were recalled in the incorrect order. Only individuals with Down syndrome participated in the online experiment and their results were in the predicted direction. Their mean auditory and visual digit spans were 3.2 and 3.3, respectively, quite similar to values reported in published studies.
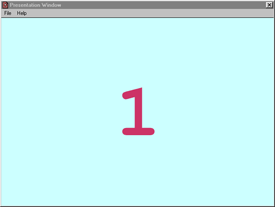
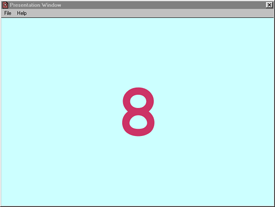
Figure 11. Example of response screen from the visual digit span task of the online experiment
The online experiment also included a task - memory for lateral orientation - that has not been used before with either population. We included this task in order to implement Mueller et al. 's (2000) suggestion that marker patterns (digit span results) be measured along with assessments of new effects (lateral orientation results); that " ...confirming old truths in a novel context is still comforting when trying to assess the legitimacy of newer findings," (p. 207). Following practice trials, the participant studied four pictures for 3 seconds apiece. Afterwards, each picture and its mirror image were presented side-by-side in random order (see Figure 12). The participant used the mouse to select the correctly-oriented picture. This task was repeated across four randomly-ordered sets of four pictures. Our hypothesis was that individuals with Williams syndrome will score below chance expectation given their apparent difficulty in visual-spatial tasks (e.g., Bellugi, Wang, & Jernigan, 1994; Pani, Mervis, & Robinson, 1999). Only individuals with Down syndrome participated in the memory for lateral orientation task, and the results indicated that they scored above chance expectation (70% of their lateral orientation judgments were correct).
Key elements of our online experiment included the presentation of graphical, auditory, and textual items, the collection of timed responses via mouse clicks, the use of a volume adjustment routine, the incorporation of reinforcing feedback (cute pictures), the gathering of data on about 100 variables, and randomization at all levels. The mean time needed to complete the experiment was 18 minutes, 26 seconds.
Pilot testing
We pilot tested the programs locally and remotely on friends and family before publicly posting the studies on the Web. Given the diversity of computers used online, it was particularly helpful to test the programs on older, slower computers with dial-up connections. Also, because Authorware is a cross-platform application, we had assumed that our web-packaged programs would work on both PCs and Macintoshes. However, the cross-platform aspect of our project brought back memories of my childhood, when I was immersed in the realm of DC comic book heroes like Superman, Green Lantern, and the Flash. I could not understand why anyone would want to read Marvel comic books with heroes like Spider Man, Hulk, and X-Men - characters who came from a completely different, non-overlapping universe. PCs and Macs - even when operating cross-platform software - have also apparently evolved in separate, non-communicative universes. We spent days running back and forth across campus from PCs to Macs, trying to get fonts to match, sound to work, and data to transfer correctly. We eventually learned how to create font-equivalency text files, convert stereo sound files to mono, and work around data transfer problems in which there was an incompatibility between browser and computer. 3 Ironically, all of the participants to date have completed our studies on PCs.
Recruiting participants
One of the most surprising aspects of our online research experience to date has been the difficulty we have had reaching the targeted populations. We discuss below the two types of recruiting methods we used, active and passive recruitment ( Bailey et al., 2000 ).
Active recruiting method
'Active recruiting' involved distributing to targeted groups an email invitation to participate ( Bailey et al., 2000 ). In the email message we introduced ourselves, briefly described the purpose of the project and the tasks, gave assurances about the anonymity of participation, provided a clickable link to our web page, and asked that the message be forwarded to interested parties. We tried to keep the message as brief as possible, with detailed information being presented on the initial web page and again on the consent form. We approached only those organizations that we thought would be interested- generally parent support discussion groups and web sites on Down syndrome and Williams syndrome (there are far fewer of the latter). We did not submit notices to child or adolescent chat groups or to commercial websites, such as those for medical centers that specialise in working with individuals with Down syndrome. The messages went directly to webmasters of national sites, moderators of discussion groups and bulletin boards, and email contact persons for local support groups and listserves.
In the first wave of active recruiting we sent messages to 24 presumably up-to-date informational web pages, professional societies, regional parent support groups, and special interest listserves. [Many potential contacts located with search engines were quickly eliminated because their sites appeared to be outdated (beware when the most recent event is the 1998 Christmas party, or when the page begins with the banner, "1999 promises to be a very good year!"); furthermore, numerous links listed on pages of national organizations did not work, and email addresses of contact people were often invalid.] We took Buchanan's (2000) advice and monitored our initial email submissions to Down syndrome and Williams syndrome sites to see whether they elicited an announcement, hostile replies, or discussion of the studies. Disappointingly, only 9 of the 24 sites (a cooperation rate of about 38%) had posted or forwarded our message two weeks after submission . Of the sites where the online project had been announced, there was no evidence of hostile responses or discussion of the studies. The only bulletin board response to the initial recruiting announcement was a helpful comment that the URL link in our recruitment letter could not be clicked. Explanations of the low cooperation rate might include the time of the year (August vacation), the fact that several sites appeared to be unattended (a recent revision date was listed on the front page, but old messages and events were posted within the site), and the possibility that webmasters and bulletin board moderators believed that their web site was an inappropriate venue for online recruiting.
We next sent a wave of email recruiting messages to 24 different, seemingly active, local (city-based) Down syndrome and Williams syndrome web sites. A 4-week follow-up yielded even more disappointing results: The message appeared to have been forwarded or posted in only 5 of the 24 sites (a 21% cooperation rate). One of the issues we are currently considering is the proper 'netiquette' of making a follow-up email announcement a few weeks after an initial announcement (parallel to the second mailing of a survey). Here are some practical tips that we would like to pass along based on our initial active recruiting experiences:
- Bulletin boards often do not allow you to post a message unless you join. And, after you join and post your announcement, you may learn that no one has read or posted an item during the past 6 months.
- Some listserves will not forward your message to its membership because the individual in charge of postings cannot make that decision (in one case we were given a long-distance phone number of a person to call who could make the decision).
- Some bulletin board programs automatically render your URL non-clickable, erase your link, and/or truncate your message.
- Keep in mind the amount of unwanted email people routinely get. It is important to make a recruiting message clear and brief, and to consider the possibility that it might be deleted before it is read.
An unanticipated benefit of active online recruiting was the direct email feedback received from participants. On the basis of very early comments and questions from a few recipients, we made the following changes to the recruiting letter: a) Originally, the wording stated that the experiment would be completed by a mentally handicapped individual 'with the assistance of an adult.' This was changed after the parent of a 31-year-old individual with Williams syndrome pointed out that it implied that his daughter was not an adult; b) We added the word 'brief' to the description of the survey after learning that the first several participants easily completed the survey in under 10 minutes; and c) Upon inquiry by a participant, we added an assurance that the information would not be used for commercial purposes.
Passive recruiting method
Our passive recruiting method involved submitting the project's URL to search engines in the hope that users would come upon our study when searching for related information ( Bailey et al., 2000 ). Most search engines like Alta Vista, Excite, HotBot, or WebCrawler use indexing software robots called 'spiders' that crawl the Web and search URLs for information to index. Although spiders will eventually find your web page on their own, one can speed up the detection process by submitting a URL directly to the search engines. Different search engines have different submission procedures and criteria for indexing, and a few - Yahoo being the most popular - require that the submitter determine the most appropriate subcategory in which to list the website (e.g. one of the Yahoo categories to which we submitted this project was Health > Disease and Conditions > D > Down Syndrome). We used free submission services (e.g. Submit Express, SelfPromotion.com) that automatically submitted our URL to numerous search engines after completion of a simple form.
Here are a few tips based on our initial passive recruiting experience. Search engines typically look for keywords and phrases embedded within the HTML header of a home page. These are called metatags, and they are a critical step in the proper indexing of a study. The most important metatags are the title tag, the description tag, and the keywords tag. These should directly relate to the content of a site, and there are many online tutorials on how to use them effectively. Metatags are the web page equivalent of embedded keywords in an APA-style abstract, which heighten the likelihood of uncovering the study when a user searches an electronic database with the critical terms. The metatags used in our online project can be viewed by going to the initial web page ( https://www.cofc.edu/~marcellm/testaw.htm ) and switching to the HTML text view by clicking View>Source (Internet Explorer) or View>Page Source (Netscape) in the toolbar.
One type of free service that we found useful provided an online analysis of the metatags used on our webpage (e.g. MetaMedic). We learned that we had barely acceptable metatags which used less than 50% of the space allowed, and that we needed to add more information to the tags and more descriptive text (actual text read by the user, not the hidden HTML tags) to the web page itself. We also learned that our web page had 'poor keyword relevancy to page content,' meaning that the metatags did not match up well with the content of the page. So, to heighten our chances of a decent positioning within search engines, we redesigned the visible text of the web page to be redundant with the hidden metatags and included more information than the participant really needed.
Search engines take anywhere from hours to weeks to index a site. For instance, HotBot listed our URL on the day of its submission, but Yahoo had not listed it six weeks after its submission. Once listed, a site is likely to face very steep competition for a high ranking. Engines that rank a URL by the number of external links to the site will likely rank a new site quite low. A low ranking means that a site appears as, say, hit number 891 out of 2,000; it is doubtful that anyone will scroll that far in the listings to find the site. It can also be hard to determine manually whether a search engine has actually indexed your URL. This can be addressed, however, by paying a nominal fee to a 'position checking service,' such as WebPositionGold or PositionAgent, which automatically checks the presence and ranking of a site.
All in all, we have much to learn about positioning ourselves for greater visibility on the Web. Our initial foray into active and passive recruiting yielded fewer than 30 participants- far too few to make the online research effort worthwhile. 46% of this initial sample reported reading about the project in a discussion group posting, 35% were referred by a friend's e-mail message, 19% heard about the studies by word of mouth or other means, and none discovered the project by search engine. In future studies, to track more precisely which form of recruiting yields more participants (e.g. active email announcements or passive search engine submissions), it might be useful to follow Mueller et al. 's (2000) suggestion and use different URLs (e.g. one for email recruiting and one for search engines). Investigators could then record which source led to a participant's arrival by noting the URL from which the user ran the program. Other creative avenues of recruiting might also be investigated, such as advertisement-like banners on relevant web pages or announcements in traditional print media. We noted, for instance, a handful of new participants following the publication of our email recruiting letter in a 'snailmail' Down syndrome regional newsletter.
Human participants issues in online research
Because our online project was among the first Internet studies reviewed by the College of Charleston's Institutional Review Board (IRB), our IRB application included sample screens of the program and links to other sites that conduct online research. The links demonstrated, for instance, that the standard online consent form uses an "I agree"-style button rather than a complicated password login procedure. We briefly summarize our thoughts below about some of the ethical issues in Internet research (cf. Smith & Leigh, 1997).
Consent form
The purpose of the consent form is to give participants enough information about a study so that they can decide whether to participate. Who actually reads an online consent form and agrees to be a participant will be strongly influenced by who is targeted for recruiting. In our online survey and experiment the targeted population was clearly parents of handicapped individuals. Consent was freely given by choosing to proceed with the download, and consent was freely withdrawn at any time by exiting the browser. There was much greater freedom to withdraw - and much less social pressure to participate - than is found in traditional laboratory studies. As Mueller et al. (2000) put it, " ...it is hard to imagine a more 'voluntary participation' format than Web surfing. For this reason if no other, it seems wise to keep the consent form as brief as possible."(p. 202). It should also be noted that in our online studies the consent form had a second, very practical purpose in addition to providing information: It gave the participant something to read while the experiment was downloading.
Privacy and confidentiality
Like Mueller et al. (2000), we gathered online data in a completely anonymous fashion and did not collect last names or email addresses that would identify users. In future studies, however, we believe that it would be useful to allow participants to voluntarily submit their email addresses separately from their data. This would allow for the creation of a list of 'regulars' who could be notified when the results of a study are in, or when a new study has been posted, or when the next component of a longitudinal study is ready. The list could be stored with no identifying links to the actual data.
Risks and benefits
Although adults may be the targeted participants for an online study, there is no way to guarantee that minors will not stumble onto a project. In describing our study we stated that it was intended for parents, and we avoided language like, "Minors are forbidden to participate without parental approval," because we believe that many youngsters would see this as a challenge or an invitation. Investigators should simply acknowledge that anyone of any age or background can access an online study. Given the dry content of most studies, it is highly unlikely that interlopers will stay. Before a study is posted online, researchers should ask themselves this question: "If non-targeted individuals like young children participate, is any potential harm done by their participating?" If the answer is "no," then, in our view, a critical ethical hurdle has been passed.
As a former chair of an IRB for four years, I believe that a key human participants issue in Internet research should be content: What kinds of tasks and questions are being put online? What is the nature of the stimuli? Are the questions potentially offensive to certain groups of people? What can be done to minimize the likelihood of those groups coming upon the study? These are questions that IRBs often do not ask, for fear of infringing on academic and scientific freedoms. In a time of universal access, however, these seem like relevant questions to ask.
Establishing the validity of online data
Most online researchers who have worked to validate their studies appear to favour one of two methods, replication across settings and conceptual replication (Krantz & Dalal, 2000).
Replication across settings
Replication across settings is a convergent validity approach (Krantz & Dalal, 2000) in which computer-based experiments are run remotely over the Web and simultaneously in a traditional laboratory setting. Validation is operationally defined as the replication of results across new and established settings. Validation of online experiments using replication across settings has been reported, for instance, by Birnbaum (2000b) for decision-making tasks and by Pagani and Lombardi (2000) for a facial emotion judgment task. One consideration when replicating results across settings is to avoid overlap of the two samples by excluding online responses from the local domain.
The initial tendency for users of this method of validation is to view the traditional laboratory-based mode of data collection as providing the 'gold standard' for validation of the online sample. Reips (2000), however, turned this way of thinking on its head and suggested that Web experiments, which have several advantages over traditional laboratory experiments, might provide an excellent way of validating traditional lab research. For example, he noted that traditional experimental psychology studies use participants of convenience (college students), whereas typical Web studies use demographically diverse samples, and that Web studies are less prone to experimenter bias and demand characteristics than traditional studies which use a physically-present experimenter.
Conceptual replication
Conceptual replication is a construct validity approach (Krantz & Dalal, 2000) in which the results of online research are compared to well-established outcomes (marker patterns) predicted on the basis of previous studies. Mueller et al. (2000), for instance, conceptually replicated patterns of findings on test anxiety, and Krantz, et al. (1997) conceptually replicated published findings on the determinants of female attractiveness. Conceptual replication was the validation approach used in our online survey and experiment.
Regardless of the validation method used, online studies have thus far yielded results similar to those generated in traditional laboratory studies. In a review of the validity of online experiments, Krantz and Dalal (2000) found a pattern of congruence - sometimes even an interchangeability of data - between online and traditional laboratory studies. In a review of the validity of Internet (e-mail) surveys, Krantz and Dalal (2000) suggested the following: a) Electronic surveys appear to be equivalent to traditional mail surveys in response rate and content of answers; b) E-mail surveys are less expensive and give faster results; and c) Participants appear to write more in electronic surveys and to give more complex comments than in paper-and-pencil surveys. Baron and Siepmann (2000), who have extensively used both paper-and-pencil and Web surveys in their research, also concluded that the Web survey approach tends to produce the same kinds of effects as the paper approach and has several advantages over the paper approach.
Disadvantages of online experimentation
Numerous researchers have provided similar descriptions of the disadvantages and advantages of online research; two of the most useful summaries are those offered by Reips (2000) and Schmidt (1997). We briefly review the major disadvantages and advantages of online research in the following sections.
Difficulty recruiting participants
As discussed earlier, attempts to post messages with support groups, informational web sites, and bulletin boards can be frustrating- the links are often old, the message boards unused, and the emails unanswered. Search engines can be quite slow to index a URL, and the competition for a high site ranking quite steep. Clearly, email recruitment needs to be an ongoing process and studies need to be posted online for long periods of time in order to allow for detection and ranking by search engines.
Biased demographics
Krantz and Dalal (2000) reviewed evidence suggesting that online participants tend to be white, American, English-speaking, young adults. Common sense also suggests that participants overly represent certain groups, such as families with Internet-connected computers, higher income levels, and more years of education. Because of these biases, it is important to gather demographic information on an Internet sample in order to know to whom the results generalise. This is something that researchers who work with special populations fully understand because they have always had to rely on convenience samples. The presence of a biased online sample could be evaluated by comparing its demographic characteristics with those of traditionally recruited samples.
One finding from Web-based studies in psychology is that online samples are sometimes more representative in terms of sex distribution, age, income, etc., than campus samples (Baron & Siepmann, 2000; Schmidt, 1997). It is also surprising to learn that the Internet is not as heavily dominated by highly educated, high income males as it once was. A good barometer of who is out there is the ongoing Georgia Tech Graphic, Visualization, & Usability Center's Survey of WWW Users ( https://www.cc.gatech.edu/gvu/user_surveys/ ), which has noted slow but steady democratising changes in the core demographics of Web users. It is important to acknowledge, however, a clear bias in any online sample: The respondents will definitely be users of computers ( Mueller et al., 2000 ).
As expected, our sample included mostly middle- and higher-income families (50% reported having family incomes over $50,000; 36% under $50,000; and 14% preferred not to answer) from the United States (one participant was from Canada and one from Europe). The typical respondent was a middle-aged (mean age 41.7 years), married (90%), Caucasian (100%), female (90%) with a college degree (43%; 29% reported completing some college; 14% some graduate work; and 14% reported completing high school). It is interesting to note that unlike the typical young adult male users of the Web, our sample consisted largely of middle-aged mothers.
Self-selection
When people are given a choice to participate and do so, they have selected themselves into the study. Self-selection reduces external validity (the ability to generalise results). In all fairness, however, it should be noted that self-selection occurs in virtually all psychological research. Some people talk to the dinnertime telephone surveyer and others hang up, some parents return the school-based research recruitment letter and others throw it away, some students sign up to participate in lab experiments and others do not. The fact is that virtually all of our research depends on self-selected volunteers.
Differences in computers, monitors, and speakers
One of the strengths of laboratory research is its high internal validity (the ability to exert experimental control over confounds). Experimenters present stimuli and record responses in highly standardised environments in which factors such as monitor size are held constant across participants. In the wilderness of the World Wide Web, however, equipment cannot be held constant. This said, we have yet to encounter computer-based research in which homogeneity of equipment is essential to finding an effect. Pagani and Lombardi (2000) recently found, for instance, that the various kinds of software and hardware used in an online picture judgment task had no effect on the patterns of results, which were the same as those found in a laboratory version of the task. In fact, heterogeneity of apparatus might be viewed as a strength, not a weakness, of online research. Equipment differences may have little impact on participants' responses and may actually strengthen the external validity of results.
We found that participants ran our programs on a variety of hardware and software settings. The screen heights and widths of their monitors ranged from 480 x 640 pixels (8%) to 1024 x 1280 pixels (12%), with the most common setting being 600 x 800 pixels (54%). Screen depth ranged from 8 bits (15%) to 32 bits (15%), with the most common setting being 16 bits (54%). The operating system was some version of Microsoft Windows- either Windows 98 (65%), Windows 95 (27%), or Windows NT (8%). Our programs were run over both Microsoft Internet Explorer (62%) and Netscape (38%) browsers on computers that typically had fast (48%) Internet connections (43% described the connection speed as moderate and 9% as slow).
Lack of control over setting variables
Online researchers work in an unsupervised environment in which precise experimental control over extraneous variables such as type of computer, lighting, noise, and time of day is not possible. This is a potentially serious issue, for instance, in studies that use psychophysical or signal detection paradigms and that require careful control over lighting, distractions, and so on. It remains to be seen, however, whether such extraneous variables influence the integrity of results in other types of online studies. Many experiments in cognitive psychology - particularly those involving the investigation of basic attentional, memory, and reasoning processes - yield results that are highly robust to changes in setting variables. Although traditional laboratory research represents a commitment to high internal validity (experimental control) at the cost of lowered external validity (generalisability), it is conceivable that some kinds of online experiments might offer the possibility of improved external validity with inconsequential reductions in internal validity should they prove insensitive to the kinds of experimental control issues just described.
Most of the participants completed our online survey at home (71%), although some completed it at work (29%). Participants completed the survey at all times of the day, with 38% finishing it in the afternoon, 33% in the evening, 24% in the morning, and 5% late at night. When asked to assign a rating to the item, "The number of distractions in my current surroundings could be described as," using a 7-point scale with 1 as 'Very Low,' 4 as 'Average,' and 7 as 'Very High,' participants rated their environment as average in distractions (M = 3.7, SD = 2.3).
Difficulties downloading programs and plugins
This was clearly a problem in our online survey and experiment, each of which required the downloading of a large browser plugin. Families in real-world settings have computers with widely differing storage capacities and connection speeds, many of which are not the latest and greatest.
It is doubtful that online researchers with special populations will be able to employ the newest technologies (e.g. very few of today's home computers are equipped for voice recognition), and is likely that online researchers will need to continue to develop programs that target the average family user rather than the optimal power user. This technological constraint will not be as confining for online experimental psychology sites whose traditional target population - college students - have campus access to up-to-date computers with fast cable Internet connections ( McGraw et al., 2000 ).
Participants are unmonitored and anonymous
The unsupervised, remote nature of Web-based data collection may influence the integrity of the data collected. There is absolutely nothing to prevent participants from giving dishonest or mischievous answers. It should be noted, though, that this is also a problem in any research in which participants complete questionnaires, respond to stimuli, or take standardised tests without an investigator directly monitoring their answers. Although experimenters do not typically monitor participants' answers in laboratory settings, one might counter that the simple physical presence of an experimenter is sufficient to discourage dishonest and mischievous answers.
In reporting on a 16-year-old online research participant who claimed to have a Ph.D., Pasveer and Ellard (1998) noted that,
"This particular problem is not unique to Internet data collection....The Internet, in fact, may be less likely to elicit erroneous responses. Since responses are obviously anonymous and confidential, respondents may be more honest with their answers...The best we can do as researchers is to inspect responses and eliminate any answers that are obviously incorrect." (p. 313)
One way to address the issue of the integrity of answers is to incorporate 'validity checks' in which the same question is asked more than once to see whether the answer changes, or to ask a question that has known desirable but unlikely answers. Our survey, for instance, included a validity question about the type of computer the participant was using, even though that piece of information was automatically gathered by the program. Our notion was that if a participant tended to give contrary answers, then this answer might also be inconsistent. (By the way, we found that our 'validity question' was answered correctly by all participants.)
Incomplete responses and attrition
The issue of incomplete responses is certainly an important area of concern - one cannot remotely persuade a participant to complete all items. However, one can set up a program so that incomplete responses are not allowed. In both of our online studies, participants could not progress until an answer was given. If they wished to stop, they simply exited, and we did not collect the incomplete responses. This practice, however, does not address another problem - participant mortality (attrition) - which does indeed appear to be greater in online than traditional research (Reips, 2000). Web research participants are likely to have a lower commitment to completing a research project (e.g. a mother participating online has not driven 30 minutes to get her child with disabilities to the campus for testing). The social dynamics involved in quitting an online study are not nearly as daunting as those involved in quitting a lab study!
One way to estimate the attrition rate is to include a counter on the web page that launches the study and to compare the counter total with the total number of individuals who actually completed the study (after, of course, subtracting your own visits and those of your friends and family to the web page). Because high drop-out rates threaten both the internal validity of a study (particularly when there are differential attrition rates in the experimental conditions) and the representativeness of a sample, researchers need to go to special lengths to make their online studies short, interesting, and worth the participant's time. Reips (2000) suggested that drop-out from a study can be minimized by using a lengthy warm-up phase before the study actually begins, thus provoking early drop-out before data collection and building commitment to the study once it has begun.
Multiple submissions
Repeat participation in online research is particularly likely in studies in which people answer personal questions and get rapid feedback about themselves, or in studies in which people want to show the 'cool stimuli' or 'personal questions' to their friends. In these situations researchers sometimes collect data about the domain name server (DNS) or Internet protocol (IP) address of the participant's computer and remove from consideration multiple entries from the same location (Pasveer & Ellard, 1998; Schmidt, 1997; Smith & Leigh, 1997). This is a conservative procedure (e.g. if a family has friends over and a second participation occurs on the same computer, then these data are omitted). Moreover, monitoring multiple submissions for repeated IP addresses is becoming increasingly difficult with the use of proxy servers and dynamic IP addressing. Interestingly, Reips (2000) conducted an online learning experiment before the onset of these developments and found, by checking both static IP addresses and email addresses, that only 4 of 880 submissions (a multiple submission rate of less than half of 1%) needed to be excluded. Likewise, in an online sex survey from 1995-1999 with over 7,000 respondents, Bailey et al. (2000) reported that multiple submissions from the same IP address were rare.
Monitoring multiple submissions may eventually prove unnecessary for some kinds of studies. As Reips (2000) put it, "Generally, multiple participation by the same persons is not very likely, as most Web experiments are not that thrilling. It seems unlikely that people would repeat long or boring experiments," (p. 107). It should be noted that if a multiple submission is accidental (e.g. sending the same data more than once), this will likely be readily noticed by the researcher.
Inability to clarify instructions
An online experimenter is not readily available to answer a participant's questions. However, if the tasks and instructions are clear and if ample practice trials and feedback on practice performance are given, then it is unlikely that instructions will need clarifying. Thorough and rigorous pilot testing should result in instructions that are easy to follow online.
Advantages of online experimentation
Potentially large number of participants
The primary attraction of online research is the promise of large sample sizes. There are millions of people using the Web, most of whom have never been involved in research. One estimate by the Computer Industry Almanac (https://www.c-i-a.com/) is that by the year 2002, there will be 490 million individuals around the world with Internet access. As Reips (2000) put it, "Web experiments allow people to experience psychological research who would never have had the chance to do so due to geographical, cultural, or social barriers," (p. 94). With larger samples comes increased statistical power - the ability to detect small, subtle effects. Based on our limited experience, however, getting large samples is not a given - it requires work, patience, and a long-term Web presence.
Higher external validity
Although there are still only a handful of published Web experiments, there is some evidence to suggest that Web-based samples are more heterogeneous and representative than the convenience samples usually seen in experimental psychology laboratory research. The kind of people included in a sample depends, in large part, on the topic of study. Pagani and Lombardi's (2000) online study of the role of the upper facial features in the communication of surprise yielded, in contrast to the stereotypical Internet user, a sample with 69% female participants - due, they thought, to the greater interest of females in the research topic of emotion. These investigators were also able to obtain sizable samples from Northern and Southern Europe as well as North America, allowing them to make cross-cultural comparisons, a practice which is becoming easier as the Internet spreads to more users across more nations (Hewson, Laurent, & Vogel, 1996; Smith & Leigh, 1997).
Large numbers of participants recruited from varying geographic regions and varying demographic backgrounds, tested on different machines in different settings, creates excellent generalisation of results. And generalisation should continue to improve as Web technology becomes increasingly widespread, popular, and transparent. Nonetheless, it remains to be seen whether families with special needs children, recruited online, will be as representative as families recruited in the traditional manner for laboratory and field research.
Completely voluntary and anonymous participation
In an online study there really is freedom to withdraw at any point, with none of the usual social pressures to participate. As Mueller et al. (2000) put it, " ...one can hardly imagine a more superfluous clause to be issued to someone halfway around the world than the assurance they could stop at any point without penalty," (p. 202).
Buchanan (2000) suggested that one consequence of the greater anonymity of online research participation might be increased self-disclosure, which some researchers have indeed observed when comparing computerised and paper-and-pencil versions of tests. Buchanan also suggested that participants in online research, relative to those in traditional laboratory research, feel a stronger sense of empowerment and ownership of the research:
"Respondents gave feedback, offered help and advice, used the experiments for their own ends, and demanded more information about the studies. Perhaps because taking part in such a study requires the respondent to actively seek it out, or because respondents are more in control of the experience or engage with the research more fully, there is a very real shift from being a subject of experimentation to being a participant." (p. 136)
Like Buchanan, we noticed a strong sense of involvement on the part of some of our adult helpers. About half provided comments and feedback ranging from a simple thank-you and request for more information, to detailed recommendations about how certain temperamental traits should have been addressed in our survey and how instructions might have been improved in our experiment.
Reduction in experimenter bias and demand characteristics
The participant is not going to react to the investigator's personal characteristics in an online study. It is not obvious to a remote user that the experimenter is an overweight, middle-aged, white male with an annoying speech mannerism. (It is also not obvious to the experimenter what kinds of characteristics the participant possesses.) Because the investigator is not physically present, demand characteristics are also reduced - there are fewer situational cues to suggest to the participant what behavior is expected. As Hewson et al. (1996) put it, research over the Internet may create less of a tendency to please the experimenter and less susceptibility to conform to social norms.
As Reips (2000) noted, one of the traditional ways of controlling demand characteristics is to automate experimental procedures as much as possible, and online research is, by necessity and design, highly automated. Fewer errors (e.g. transcription mistakes, problems of deciphering handwriting, lapses of attention during data tabulation) are also likely to occur in online research because data are entered directly into a file (Pasveer & Ellard, 1998). Depending on the degree of automation of scoring, there might also be a reduction in bias related to interpretation of responses. These advantages would, of course, characterise any fully automated computer-based laboratory, whether online or offline.
It is important to recognize that if a parent is actively working as a "helper" with a special needs research participant in a home-based online experiment, then the parent becomes the experimenter's proxy, and the participant's responses may be influenced by the behavior of the parent. The presence of such reactivity should be a central concern in all online research with handicapped individuals. One way to evaluate the presence of helper reactivity would be to directly compare the performances of online and laboratory samples on the same computer-based tasks.
Savings in time and financial costs
There are many ways in which online studies are efficient. They can be useful tools for pilot testing: one can put an experiment online and get rapid feedback about the clarity of the instructions, the difficulty of the tasks, and the robustness of the effect. Results in an online pilot test can accumulate quicker because data can be collected simultaneously from numerous participants.
Online studies require a minimum of space and equipment, with the major financial expenditures being software and the training to use it. You spend no time setting up appointments with families and testing individuals, although you may spend considerable time recruiting targeted individuals and responding to email requests for more information. There are tradeoffs in the time commitment of the researcher. If you are the person who develops the program, then you will spend a great deal of time writing and testing the program, but much less time running subjects and entering data. If you are a collaborator (but not the programr) who assists in a shared research effort by testing participants on a Web-based task administered in a traditional, controlled laboratory testing, you will obviously spend much less time in program development.
It is important to note that time not spent physically testing participants may reduce the serendipitous insights that sometimes occur when observing participants. Online research is certainly no substitute for working directly with special needs individuals- this is an essential part of the learning process for experienced as well as new researchers. Any researcher worth his or her salary will always spend time in the field observing and interacting with those individuals who are the object of study.
Convenience
Online research participation occurs at the time and place chosen by the participant ( Hewson et al., 1996 ). As Reips (2000) put it, Web experiments offer the possibility of "bringing the experiment to the participant instead of the opposite," (p. 89). Say goodbye to scheduling problems and no-shows! It is interesting to note that over a third of our sample reported participating at unconventional testing times (evening and late night). Reips (2000) also raised for consideration the possibility that participants may behave more normally in online experiments than in the monitored laboratory settings in which we usually test them. Online research participants are usually tested in that most familiar of settings, their home. It is possible that the behaviors they demonstrate in this comfortable setting might be more typical than those displayed in a laboratory setting. Of course, it is also possible that the behaviors displayed in a home-based study are more contaminated in unknown ways by distractions, unwanted help from well-meaning others, and so on.
Openness
An important advantage of online research that Reips (2000) noted was the openness of the procedures to evaluation by the research community. Unlike studies reported in journals, anyone can participate in an online experiment and scrutinize its stimuli and methodology. This is a degree of openness that can be frightening and threatening at first, but ultimately liberating in terms of the useful feedback provided by colleagues and participants and the integrity and openness it brings to the research process. Ethical issues in an online research project are also completely open to scrutiny by the research community, and feedback on ethical concerns is likely to occur much faster in online research because of its easy accessibility (Reips, 2000).
Possible online applications with Down syndrome
Theoretically, any study currently conducted on a computer with individuals with Down syndrome can be carried out over the Web. Surveys, correlational studies, experiments- all of the most frequently-used research methods should be technically easy to implement on the Web (naturalistic observation, in contrast, is not especially doable). A potentially interesting avenue to explore is the online delivery of training materials directly to families and the remote monitoring of their progress. One model for this is the rapidly-expanding world of online college instruction.
The variety of topics that can be researched online should be much like the variety of topics already researched in the laboratory; examples include family issues, behavior problems, memory training, language comprehension, visual perception, problem solving, reading, reaction time, and so on. There are, of course, numerous research topics and procedures that do not yet avail themselves to online research, such as those that involve audiological exams, blood drawing, MRIs, sleep research, expressive language tasks, biofeedback, and so on.
We believe that Down syndrome researchers could strongly benefit from the collaborative and data-pooling aspects of online research. Research over the Web may be a particularly valuable option for researchers at smaller institutions (Smith & Leigh, 1997) and teachers and clinicians working in educational and medical settings. There are certainly educational and medical professionals working in the field with individuals with Down syndrome who would like to share their observations and assist in research, but who do not have the technical skills or research training to create viable studies. There are also certainly trained investigators with technical skills, research training, and viable ideas, but without the broad access to individuals with Down syndrome needed for their research. And there are just as certainly parents of children with Down syndrome who are concerned and curious and would like to be part of a larger quest for knowledge, but who have never been asked to be in a research study. It seems reasonable to hope that the Web could serve as a vehicle for bringing these individuals together in collaborative research efforts.
Models of online research with special populations
There are likely several ways to collect data from geographically-remote research participants. We wish to share what we think are two promising models for conducting online research with special populations: the parent-as-researcher model and the colleague-as-collaborator model.
Parent-as-researcher model
In this model of online research, remotely-recruited parent or adult 'helpers' act as the investigator's eyes, ears, and hands by interpreting instructions and assisting target participants in completing tasks. The central characteristic of this model is the use of an unknown individual as the experimenter's proxy to facilitate the participant's response. The critical question is this: Will helpers follow directions, act objectively, and allow their children to respond in a normal manner, or will helpers respond for their children by assisting them too much or by subtly directing their responses in the correct direction? A favourable answer will certainly involve the following practices: making task instructions simple and explicit, providing the participant with numerous practice trials, allowing the helper to demonstrate proper responses, inserting frequent reminders to the helper of his or her role in the task, and clearly targeting parents when recruiting in order to heighten the likelihood of actually having parents as the helpers.
The validity of the parent-as-researcher model could be enhanced by online replication of well-established findings that are not particularly well-known or 'transparent' to parents. One concern is that if parents are knowledgeable about a topic and have expectations about the outcome, then they might act in a way to fulfil that prophecy. At least in initial online studies, it might be helpful to work with well-understood tasks that are likely to yield counterintuitive or hard-to-predict findings.
It is also possible that the parent-as-researcher model might prove useful as an adjunct to ongoing research projects. That is, an investigator might collect data in the usual manner by bringing participants into the lab, going to local schools, or visiting families' homes with a laptop computer. At the same time the investigator might post the same study online and collect data remotely with parents as experimenters. The question is this: Do the two parallel research efforts yield the same patterns of results? If they do, then confidence builds in the internal validity of the online results and the external validity of the laboratory results.
Colleague-as-collaborator model
In this model of online research, remotely-recruited colleagues test participants in traditional laboratory or field settings, but share online tasks and pool data in a common online archive. The central characteristic of this model is the recruiting of geographically remote colleagues (perhaps even in different countries) to join in a traditional data collection effort. An important advantage of the colleague-as-collaborator model is that the usual experimental controls are offered by the investigator. Data are gathered in a specified and supervised manner by trained professionals. It is the scope of data collection that differs: data collection is spread out over different researchers working in different locales. This is nothing new- it is simply collaborative research facilitated by online technology.
Studies that are shared by colleagues who are interested in the same topic - or who are at least willing to take turns helping each other out - would create challenges. For instance, there is the ever-present sense of intellectual possession and territoriality, as well as the inevitable likelihood that one person will get stuck with most of the work. Established researchers may not want to make time to work on others' research efforts, and those who have a strong need to control their environment will likely be uncomfortable with unwashed strangers handling their baby. However, there are potential benefits of the colleague-as-collaborator model that should be noted. Shared samples will be larger and more heterogeneous, direct assessments can be made of experimenter effects, and publications may come faster. For young researchers there may be a more rapid immersion in the research process, for educators and medical professionals without research training there is the possibility of participating meaningfully in the research process, and for the technologically disabled, the pain suffered in developing a working computer program can be shouldered by another.
How to implement the models?
We believe that there are two primary ways that either the parent-as-researcher model or the colleague-as-collaborator model could be implemented in online research: the informal, independent approach and the formal, interdependent approach.
The informal, independent approach
In this approach the investigator locates and contacts the usual online bulletin boards and listserves, recruits participants, sets up independent working relationships with parents or colleagues, and develops technological solutions to the various online research issues. This ad hoc, casual, self-contained approach is the one we piloted in our online survey and experiment, and it certainly seems a reasonable way to begin. One can envision several research laboratories developing their own approaches to online research and learning from others' mistakes in a kind of evolutionary, natural selection process. To some degree, this process is occurring today in numerous online cognitive psychology experimentation sites. There are, of course, challenges such as different researchers over-soliciting the same participants, individuals posting redundant research efforts, and one person's rude mistakes spoiling another's opportunities.
The formal, interdependent approach
Imagine this: a person or a group applies for a grant to develop a World Wide Web clearinghouse for research with special populations. This site could follow the cognitive psychology PsychExperiments model ( McGraw et al., 2000 ) in which:
- The developers create the initial web site and post the initial studies
- Training in the authoring tool is offered by the developers to interested researchers
- The site is 'owned' by a community of researchers and not just the original creators; input by others keeps it fresh and changing
- Researchers post announcements to solicit collaborators for a research effort
- Technical support is provided by a paid employee knowledgeable in computer matters
- The site is linked to by support groups and societies and becomes a place where interested parties can regularly visit to participate in studies
- Visitors to the site who volunteer their email addresses are contacted whenever a new study is posted or the results of an old study are available
The advantages of the formal, interdependent approach for researchers at small institutions are obvious in terms of reduced operating costs, savings of time, and intellectual cross-fertilization. Another very important advantage is data pooling. As McGraw et al. (2000) noted, " ...having a single Web-based implementation of an experiment allows data to be pooled across research sites and across time. With data pooling, the types of questions addressed in laboratory work can be answered using large data sets in place of the typical small ones," (p. 220). The PsychExperiments site provides an excellent online model of how to publicly share data. Demonstration-style experiments (such as the Stroop effect, used primarily for undergraduate instruction) allow archived, publicly available data to be available for download and analysis. For actual posted research studies, investigators have the option of making data available publicly.
Concluding thoughts
A global nexus of interconnected computers is rapidly becoming a central element of today's world. The manuscript you are now reading includes references to articles that were initially located online using the PsycINFO electronic database, ordered electronically from home or office by email, and rapidly retrieved and forwarded by our College's wonderfully efficient interlibrary loan system. The manuscript itself was cut and pasted from a Microsoft Power Point presentation, merged into a WordPerfect text document, and transmitted electronically over the Atlantic Ocean to the editors in England. The survey and experiment that we recently posted online were created with Macromedia Authorware; the participants were located through Web-based searches and recruited via e-mail. The studies reside on a web page, the web page resides on the College's server, and the programs can be run any time, anywhere, and by anyone in the world who has access to the Internet.
This is an exciting time of experimentation in online experimentation. We believe that the near future will bring a steady increase in online research as computers and connection speeds get faster and cheaper, hardware and software become easier to use, and the community of users becomes more representative of the general population. Economies of scale and efficiencies gained from pooled research efforts will entice researchers to post studies on the Web, especially researchers who have limited funds and resources and who work in small metropolitan areas with specialized populations. Others will be attracted by the special promise of online research: the ability to recruit larger, more diverse samples of participants, and in the process, improve the generalizability of their results.
Regardless of whether online researchers recruit parents or colleagues as experimenters, and regardless of whether researchers go about this in an informal or formal way, the goals are the same: to explore new and promising ways of doing research, to gather data in a more efficient manner, to advance our scientific understanding of the research topics in which we are interested, and to help the special needs kids we have learned to love. The time is coming when you might want to take a closer look at how online technology might be able to help you achieve some of these goals.
Acknowledgements
Portions of this paper are based on an invited address delivered by the first author at the 3rd International Conference on Language and Cognitive Development in Down Syndrome, September 6-8, 2000, Portsmouth, England. The words "I" or "my" in this written manuscript refer to the experiences of the first author, a convention preserved in order to convey the flow of the spoken address. We are indebted to Professors Ken McGraw and Mark Tew of the University of Mississippi for creating PsychExperiments, an excellent model of online psychological research, for offering training in the use of Macromedia Authorware, and for providing the software template on which our programs are based.
Correspondence
Dr. Michael M. Marcell • Department of Psychology, College of Charleston, Charleston, South Carolina, 29424, USA • E-mail: marcellm@cofc.edu
Notes:
1 There appear to be many such freeware scripts available in CGI languages for knowledgeable users to adapt and use. Our Perl CGI form-handling script was written by David S. Choi (dc@sitedeveloper.com) and adapted by College of Charleston Webmaster, Trace Pupke.
2 The primary problem we had in this stage of program development (other than having to admit ignorance and ask for help) was making sure that the variables and data transferred in the manner intended. Data were saved to a .txt file in which variables and data were separated by commas. A problem we initially encountered when importing the comma-delimited text file into Excel occurred with the final variable, SubjectComments. The plan was to import the typed feedback from subjects to Excel as one (lengthy) variable. However, if a subject used commas when typing comments, then the comments wound up being parsed into separate columns. The fix was to replace all commas in the subject's typed text with spaces before transferring the data; interestingly, Bailey et al. (2000) reported the same problem.
References
- Bailey, R.D., Foote, W.E., & Throckmorton, B. (2000). Human sexual behavior: A comparison of college and Internet surveys. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 141-168). San Diego: Academic Press.
- Baron, J., & Siepmann, M. (2000). Techniques for creating and using Web questionnaires in research and teaching. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 235-265). San Diego: Academic Press.
- Bellugi, U., Wang, P.P., & Jernigan, T.L. (1994). Williams syndrome: An unusual neuropsychological profile. In S.H. Broman & J. Grafman (Eds.), Atypical Cognitive Deficits in Developmental Disorders: Implications for Brain Function (pp. 23-56). Hillsdale, NJ: Erlbaum.
- Birnbaum, M.H. (2000a). Psychological Experiments on the Internet. San Diego: Academic Press.
- Birnbaum, M.H. (2000b). Decision making in the lab and on the web. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 3-34). San Diego: Academic Press.
- Buchanan, T. (2000). Potential of the Internet for personality research. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 121-140). San Diego: Academic Press.
- Gosch, A., & Pankau, R. (1997). Personality characteristics and behavior problems in individuals of different ages with Williams syndrome. Developmental Medicine and Child Neurology, 39, 527-533.
- Hewson, C.M., Laurent, D., & Vogel, C.M. (1996). Proper methodologies for psychological and sociological studies conducted via the Internet. Behavior Research Methods, Instruments, and Computers, 28, 186-191.
- Jones, W., Bellugi, U., Lai, Z., Chiles, M., Reilly, J., Lincoln, A., & Adolphs, R. (2000) . Hypersociability in Williams syndrome. Journal of Cognitive Neuroscience, 12 (Suppl.1), 30-46.
- Klein, B.P., & Mervis, C.B. (1999). Contrasting patterns of cognitive abilities of 9- and 10-year-olds with Williams syndrome or Down syndrome. Developmental Neuropsychology, 16, 177-196.
- Krantz, J.H., Ballard, J., & Scher, J. (1997). Comparing the results of laboratory and WWW samples on the determinants of female attractiveness. Behavior Research Methods, Instruments and Computers, 29, 264-269.
- Krantz, J.H., & Dalal, R. (2000). Validity of Web-based psychological research. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 35-60). San Diego: Academic Press.
- Marcell, M.M., & Armstrong, V. (1982). Auditory and visual sequential memory of Down syndrome and nonretarded children. American Journal of Mental Deficiency, 87, 86-95.
- Marcell, M.M., & Weeks, S.L. (1988). Short-term memory difficulties and Down's syndrome. Journal of Mental Deficiency Research, 32, 153-162.
- McGraw, K.O., Tew, M.D., & Williams, J.E. (2000). PsycExps: An online psychological laboratory. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 219-233). San Diego: Academic Press.
- Morris, C.A., & Mervis, C.B. (1999). Williams syndrome. In S. Goldstein & C.R. Reynolds (Eds.), Handbook of Neurodevelopmental and Genetic Disorders in Children (pp. 555-590). New York: Guilford Press.
- Morrow, R.H., & McKee, A.J. (1998). CGI scripts: A strategy for between-subjects experimental group assignment on the World-Wide Web. Behavior Research Methods, Instruments, and Computers, 30, 306-308.
- Mueller, J.H., Jacobsen, M.D., & Schwarzer, R. (2000). What are computing experiments good for?: A case study in online research. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 195-216). San Diego: Academic Press.
- Musch, J., & Reips, U.-D. (2000). A brief history of Web experimenting. In M.H. Birnbaum (Ed.), Psychological Experiments on the Internet (pp. 61-87). San Diego: Academic Press.
- Pagani, D., & Lombardi, L. (2000). An intercultural examination of facial features communicating surprise. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 169-194). San Diego: Academic Press.
- Pani, J.R., Mervis, C.B., & Robinson, B.F. (1999). Global spatial organization by individuals with Williams syndrome. Psychological Science, 10, 453-458.
- Pasveer, K.A., & Ellard, J.H. (1998). The making of a personality inventory: Help from the WWW. Behavior Research Methods, Instruments, and Computers, 30, 309-313.
- Reips, U.-D. (2000). The Web experiment method: Advantages, disadvantages, and solutions. In M.H. Birnbaum (Ed.), Psychology Experiments on the Internet (pp. 89-117). San Diego: Academic Press.
- Schmidt, W.C. (1997). World-Wide Web survey research: Benefits, potential problems, and solutions. Behavior Research Methods, Instruments, and Computers, 29, 274-279.
- Smith, M.A., & Leigh, B. (1997). Virtual subjects: Using the Internet as an alternative source of subjects and research environment. Behavior Research Methods, Instruments, and Computers, 29, 496-505.
- van Lieshout, C.F.M., DeMeyer, R.E., Curfs, L.M.G., &Fryns, J.-P. (1998) . Family contexts, parental behavior, and personality profiles of children and adolescents with Prader-Willi, fragile-X, or Williams syndrome. Journal of Child Psychology and Psychiatry and Allied Disciplines, 39, 699-710.

