Observational Learning in Children with Down Syndrome and Developmental Delays: The Effect of Presentation Speed in Videotaped Modelling
Children with severe developmental delays (three with Down syndrome and three with autism as the primary diagnosis) observed a videotaped model performing two basic dressing skills without prompting, verbal or otherwise, or explanation by an instructor. In a within-subjects design, dressing skills that were presented at a relatively slow presentation speed through videotaped modelling were eventually performed better than those presented at a relatively fast speed. These data in combination with evidence from this laboratory that passive modelling of basic skills is more effective than interactive modelling (e.g., Biederman, Fairhall, Raven, Davey, 1998; Biederman, Davey, Ryder, Franchi, 1994; Biederman, Ryder, Davey, Gibson, l991) suggest that standard instructional techniques warrant reexamination both from the basis of instructional effectiveness and the efficient use of the allotment of teacher time.
Biederman, G, Stepaniuk, S, Davey, V, Raven, K, and Ahn, D. (1999) Observational Learning in Children with Down Syndrome and Developmental Delays: The Effect of Presentation Speed in Videotaped Modelling. Down Syndrome Research and Practice, 6(1), 12-18. doi:10.3104/reports.93
Current instructional strategies for children with severe developmental delays often include interactive modelling techniques with instructors delivering physical and verbal guidance and social responses such as "Good job!" or "Good girl!" intended as rewards for appropriate student behavior. This is known as response-contingent prompting (Morgan & Salzberg, 1992; Skinner, Adamson, Woodward, Jackson, Atchison, & Mims, 1993 ). In interactive modelling, the instructor literally leads the student by the hand so that the student sees himself or herself as modelling the behavior (Robertson & Biederman, 1989). Other modelling techniques use passive modelling strategies (Ezell & Goldstein, 1991; Shelton, Gast, Wolery & Winterling, 1991; Wolery, Ault, Gast, Doyle & Griffen, 1991 ). Social learning theory proposes that learning can occur through simple passive observation of behavior (Bandura, 1971). Recent evidence suggests that passive observational learning may be more effective than interactive modelling as an instructional technique (Biederman, Davey, Ryder & Franchi, 1994; Biederman, Ryder, Davey & Gibson, 1991). In the 1994 study which used a within-subjects design, children were instructed in life skills under two conditions. We have discussed the efficacy of within-subjects designs elsewhere (Robertson & Biederman, 1989). Briefly, in this technique, two skills are taught to each child under contrasting instructional arrangements. In the 1994 study, one skill was actively modelled while the other was passively modelled. For the active modelling task, half the children received social prompts intended as rewards, while the remaining children received no verbal or gestural prompting by the instructor. This study confirmed the 1991 finding that passively modelled tasks were learned significantly better than actively modelled tasks and also supported the hypothesis that verbal prompting in active modelling was not helpful for children with severe delays. More recent evidence (Biederman, Fairhall, Raven, & Davey, 1998) using the same design as in the 1994 study but with rigorous criteria for the delivery of verbal reinforcement again showed that this sort of intervention produced learning no better than that in a passive modelling intervention in a group with Down syndrome and developmental delays.
It has been proposed that attention difficulties or delays in processing inhibit the formation of associations between behavior and social responses in active modelling (Biederman, et al., 1994). That is, a child may be attending to one aspect of his or her behavior and the instructor may be attending to and commenting on another. When a social reward is delivered under these circumstances, confusion may arise. It seems useful therefore to consider techniques that focus on passive learning strategies.
One such passive learning strategy uses observational learning through videotaped presentation (Hepting & Goldstein, 1996). In a 63-study meta-analysis of the relevant literature from 1978, the use of videotaped instruction in classrooms was found to be effective (McNeil & Nelson, 1991). Success has also been reported in modifying the social skills of adolescents with developmental delays (Kelly, Wildman & Berler, 1980).
Should empirical evidence show in the final analysis that videotaped modelling is no more effective than live modelling, videotaped modelling would arguably be preferable to live modelling because videotaped presentations are a less labor-intensive instructional tool. Videotaped modelling conveys realistic behavior with complex stimulus and response routines ( Houlihan, Miltenberger, Trench, Larson, Larson & Vincent, 1995 ). The effectiveness of instructional videos in teaching basic life skills to children with developmental delays is consistent with results from classroom instruction with children without developmental delays (McNeil & Nelson, 1991). The participants in this study were able to abstract the necessary skills from the videotaped model and apply them to task performance. Children with developmental delays were taught to name food items using a progressive time delay procedure with an additional stimulus embedded within the discrimination (Doyle, Schuster & Meyer, 1996). Finally, videotaped modelling presentation has a clear advantage for experimentation in that it standardizes instruction which is a useful control technique (Morgan & Salzberg, 1992).
Despite the generally positive results from instructional strategies with video presentations, modelling factors that may optimize the effectiveness of such instruction have not been systematically addressed (Morgan & Salzberg, 1992). Basic parameters that are candidates for such examination are presentation speed, number of repetitions of the modelled behavior, and duration of videotaped presentation segments. In fact, few experiments have attempted to isolate the effects of presentation speed in live modelling conditions. In one study, varying the rate of verbal passage readings to a faster or slower speed than students' usual reading rate produced no improvements in reading (Shapiro & McCurdy, 1989; Skinner et al., 1993 ). Other studies claim improved accuracy of reading is directly related to an increased presentation speed (Freeman & McLaughlin, 1984; Smith, 1979). In live modelling, experimental control of presentation speed has been limited to audio recordings with little success.
The present experiment was intended to explore timing parameters in videotaped modelling of basic skills to children with developmental delays. We used a between-subjects design to determine whether the number of presentations or duration of the video presentation are significant factors in such instruction. For half the participants, the number of repetitions (video loops) of each task presentation was held constant, while the presentation speed of the video modelling was varied. For the remaining participants, the overall presentation time was held constant while the number of repetitions of the modelled skill was varied. Each participant was also exposed to two videotaped modelling presentations at different rates of speed in a within-subjects design. This two-task procedure has been used to assess the efficacy of live modelling variables (e.g., Biederman et al., 1991; Biederman et al., 1994).
Method
Participants
Eight children (7 males, 1 female; 6-10 years of age) from schools in Toronto, Canada participated. The children were from special education classes and were assessed by the Metropolitan Toronto Separate School Board as demonstrating pervasive developmental delay (PDD). Permission was obtained from the Separate School Board for the conduct of this experiment. Written consent for participation was obtained from the parents or guardians of each of the children. Participant parameters are given in Table 1. Inclusion in this study required that each child's skills repertoire not include any of the skills modelled in the videotapes.
| Participant | Age | Sex | Diagnosis | Task (1:2) | Speed (1:2) | |
|---|---|---|---|---|---|---|
| Equal Number of Presentations Group: | 1 | 8 | M | DS/PDD | L:S | s:n |
| 2 | 10 | M | AU/PDD | B:L | n:f | |
| 3 | 9 | M | DS/PDD | B:S | f:n | |
| 4 | 8 | M | AU/PDD | B:L | n:s | |
| Equal Duration of Presentations Group: | 5 | 8 | F | PDD | B:S | s:n |
| 6 | 7 | M | DS/PDD | S:B | f:s | |
| 7 | 6 | M | PDD | B:S | f:s | |
| 8 | 6 | M | AU/PDD | L:T | s:n | |
| AU-autism, PDD-pervasive developmental delay, DS-Down syndrome, L-lacing,S-snapping, B-buttoning, T-bow tying, s-slow speed (15 frames/sec.), n-normal speed (30 frames/sec), f-fast speed (45 frames/sec). | ||||||
Materials
The apparatus consisted of dressing frames manufactured by Galt Toys (including snapping, buttoning, and lacing). Videotapes showing the frames and an adult female model's hands performing the tasks were edited for three different presentation speeds: slow (15 frames/second), normal (30 frames/second), and fast (45 frames/second). Videotapes were presented via 20-in color monitors.
Design
In this experiment, modelling speed effects were assessed using a within-subjects design in which each subject was instructed in two different skills under different presentation speeds. That is, one task was modelled at one speed, and the other was modelled at another speed. Two of three possible speeds were used (15, 30, or 45 frames per second) for each participant. Passive observation was used as the instructional context. That is subjects watched the videotape without prompting, verbal or otherwise, or explanation by an instructor. Counterbalancing of the order of speed-specific skills was arranged.
Procedure
Children were instructed in two of four possible skills, buttoning, snapping, lacing, and bow tying, through videotaped modelling. The two skills that were shown to each child were selected through teacher and parent consultation. But none of the children could perform any of the videotaped skills at the beginning of the experiment as noted above. The skills were presented by videotape. For four participants (participants 1-4), the number of repetitions for each of the two skills was held constant while the total presentation time varied. The total presentation time per skill was 7.5 min for the slow speed, 5.0 min for the normal speed, and 2.5 min for the fast speed, for each training session (total of six sessions). For the remaining four participants (participants 5-8), the total display time for each skill was held constant at 5.0 min. per session (total of six sessions) while the number of repetitions varied. The actual number of total repetitions per training session for slow, normal, and fast speeds, were respectively: 5, 10, and 12.5 for snapping, 3.75, 7.5, and 11.25 for buttoning, 3, 6, and 9 for lacing, and 2.7, 5.3, and 8 for bow tying. Table 1 gives the videotape presentation speeds for the two skills for each participant. Each child was removed from his or her classroom and, in a quiet room, seated in a chair facing a video monitor and simply asked to watch. During the instructional sessions no experimenter prompting occurred. The training sessions lasted 20-30 min each day for six daily sessions, counterbalancing for task order. Testing occurred on the first day following the final training session and consisted of the child's first physical contact with the appropriate dressing frame. Participants were asked to perform each of the two skills without further instruction, demonstration, or prompting. Performance was videotaped for later evaluation.
Performance Evaluation
Participant performance was rated by multiple judges viewing videotaped segments of participant behavior in a method described by Biederman et al., (1991). The videotaped performances by the participants were edited to 30-sec segments for each skill. The editor was unaware of modelling condition or group assignment. Subject number and task identification letters (A or B) were superimposed in black letters over a white background for 10 sec prior to each 30-sec segment.
The raters were undergraduate psychology students (N=31) at the University of Toronto at Scarborough. Written instructions with rating examples were provided and any questions were answered. Raters were untrained and blind to hypotheses and variables in the study. Video presentations were randomized for participant and task order. The advantages of the use of untrained raters has been described elsewhere (Biederman et al., 1994). Briefly, the judges were instructed to view these behaviors from the perspective of "a person in the street," on the assumption that if significant relative differences in the quality of performance in the two tasks occurred, these differences should be apparent to anyone and not as a subtle (and perhaps minor) difference detectable only to a specialist. Raters were otherwise untrained and unaware of the purpose of the study. The use of untrained judges and their effective equivalence to trained judges has been described by Wallander, Conger, and Ward (1983). It is interesting to speculate that untrained raters are likely to be, in effect, more conservative than trained raters. The latter might see important small differences in behavior and rate the performances as more different than would untrained raters who are likely to notice only large differences. Possible issues are (1) whether there is any bias introduced into the raters' judgments about the relative merits of the two tasks they judge for each child, and (2) whether the raters are competent to detect differential performance between tasks: Counterbalancing of the order of type of task first seen by the raters, randomizing the order in which videotapes of the children are seen, and lack of knowledge by the raters of the prior training history of each of the skills make it extremely unlikely that any systematic bias was introduced into the ratings. We have evidence that the raters are competent to judge differential performance through control data in Biederman et al. (1991), where untrained skills not in the repertoire of control subjects were compared with skills already in their repertoire. Untrained judges are easily able to discriminate between these performances which is appropriately reflected in the difference scores of their ratings (Biederman et al., 1991, Fig. 1, p.178). The statistical safety inherent in large numbers of raters is perhaps obvious, but the uniformity of the raters' judgments must be assessed to confirm the validity of this approach in determining instructional efficacy (cf. Aiken, 1985; Roff, 1981; Seiz, 1982). The uniformity of raters' judgments in both Biederman et al. (1991) and Biederman et al. (1994) meet strict tests of reliability (cf. Weiner, 1971; Shrout and Fleiss, 1979).
Rating Instructions
Raters were instructed to follow rating instructions read aloud by an investigator and printed on sheets distributed to the raters:
On the video monitor directly in front of you, you will see children performing two tasks each (labelled TASK A and TASK B, respectively). On the rating sheet given to you, indicate your judgment of the relative performance quality of the two tasks that you will see. Place a mark at the place which represents your opinion of the relative quality of the performance of the two tasks. Please wait until you have seen both tasks performed before you form an opinion.
_______ _______ _______ _______ ___X___
This rating would mean TASK B was much better than A;
CHILD 2: TASK A TASK B
_______ ___X___ _______ _______ _______
This rating would mean TASK A was somewhat better than B;
CHILD 3: TASK A TASK B
_______ _______ ___X___ _______ _______
This rating would mean that TASK A and B were performed equally well.
Results and Discussion
Interrater reliability was calculated using analysis of variance (ANOVA) according to a method described by Weiner (1971) and Shrout and Fleiss (1979). The interrater reliability was consistent with previous studies from this laboratory (R=0.97, p<0.05) (Aiken, 1985; Biederman, et al., 1991 & 1994; Seiz, 1982). The value of the effective reliability of judges (R) shows that judges as a group were very reliable in assessing relative task differences. Figure 1 shows the mean of the judges' ratings giving their assessments of the relative performance quality for the two skills for each participant. One purpose of this study was to contrast videotaped modelling under conditions which permitted the total number of presentations to vary with conditions which permitted the total exposure time to vary. However, it became necessary to exclude participants 7 and 8 from statistical evaluation when, during the course of training, the experimenter learned that they were incapable of the level of manipulation required for inclusion in this study. The relative performance ratings for participants 7 and 8 are consistent with their failure to manipulate either of their tasks on test and may be considered as control ratings (see Figure 1). When the mean ratings of participants 1-4 (number of presentations equalized) are compared with the ratings of the remaining two participants (duration of presentation equalized), the participants in the former group show higher ratings for their slower-presented skill, t(4)=1.21, but the comparison fails to reach the value required for statistical significance at the conventional alpha level of .05 [t(4)=2.78, two-tailed]. However, the direction of the finding suggests that these factors should be considered for future research.
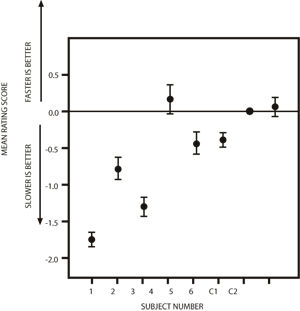
Figure 1. The mean of the judges' ratings for each child. A rating greater than 0.0 indicates better performance on the faster modelled task and a rating less than 0.0 indicates better performance on the slower modelled task, on a 5-point scale. Vertical lines depict standard errors of the means.
Combining data from the remaining six participants, a paired samples t-test for differences between relatively slower and faster presentation speeds showed that performance of skills modelled under slower speeds were rated significantly better than those modelled under faster speeds, t(5)=2.64, p< 0.05.
In addition to the finding that relatively slower speeds of videotaped presentation of skills modelling to children with Down syndrome and developmental delays significantly improved the eventual performance of such tasks, the results of this experiment are also consistent with the use of observational learning without verbal prompting intended as reinforcement as in Biederman, et al. (1994). These data suggest that better learning may result by permitting children with severe delays sufficient time to process observational information. It further reinforces the view that standard classroom instruction and individual instruction using interactive modelling strategies may be less efficient than simple observational arrangements for children with severe delays. Our evidence suggests that video presentation of modelled skills at an appropriate speed has potential as a powerful instructional medium which could have interesting implications for teachers and clinicians in group contexts. Information that different speeds of video presentation may be differentially effective for children with and without developmental delays presents clear challenges for instruction in inclusive, mixed-ability setting.
Acknowledgement
Supported by a grant to GBB from the Social Science and Humanities Research Council of Canada. The authors are grateful to the students, teachers, and parents of the Metropolitan Toronto Separate School Board who participated in this study and to Mr. Trevor Wilson of the Board for his advice and assistance in facilitating this research. The authors thank the anonymous reviewers for respectively pointing out an omission concerning the pre-instructional performance levels of the children and for suggesting some additional implications of this research.
Correspondence
G.B. Biederman, Division of Life Sciences, University of Toronto at Scarborough, Scarborough, Ontario, Canada, M1C 1A4. (Tel: 416 287 7433, Fax: 416 287 7642, E-mail: bieder@scar.utoronto.ca)
References
- Aiken, L.R. (1985). Three coefficients for analyzing the reliability and validity of ratings. Educational and Psychological Measurement, 45, 131-142.
- Bandura, A. (1971). Social learning theory. New York: General Learning Press.
- Biederman, G.B., Davey, V.A., Ryder, C., & Franchi, D. (1994). The negative effects of positive reinforcement in teaching children with developmental delay. Exceptional Children, 60(5), 458-465.
- Biederman, G.B., Fairhall, J.L., Raven, K.A. & Davey, V.A. (1998). Teaching basic skills to children with Down syndrome and developmental delays: The relative efficacy of interactive modelling with social rewards for benchmark achievements and passive observation. Down Syndrome Research and Practice, 5(1), 26-33. [Read Online]
- Biederman, G.B., Ryder, C., Davey, V.A., & Gibson, A. (1991). Remediation strategies for developmentally delayed children: Passive vs. active modeling interventions. Canadian Journal of Behavioral Science, 23, 611-618.
- Doyle, P.M., Schuster, J.W., & Meyer, S. (1996). Embedding extra stimuli in the task direction: Effects on learning of students with moderate mental retardation. Journal of Special Education, 29(4), 381-399.
- Ezell, H.K. & Goldstein, H. (1991). Observational learning of comprehension monitoring skills in children who exhibit mental retardation. Journal of Speech and Hearing Research, 34, 141-154.
- Freeman, T. & McLaughlin, F.F. (1984). Effects of taped-word treatment procedure on learning disabled students' sight word oral reading. Learning Disability Quarterly, 7, 49-53.
- Griffen, A.K., Wolery, M., & Schuster, J.W. (1992). Triadic instruction of chained food preparation responses: Acquisition and observational learning. Journal of Applied Behavior Analysis, 25, 193-204.
- Hepting, N., & Goldstein, H. (1996). Requesting by preschoolers with developmental disabilities: videotaped self-modeling and learning of new linguistic structures. Topics in Early Childhood Special Education, 16(3), 407-427.
- Houlihan, D., Miltenberger, R.G., Trench, B., Larson, M., Larson, S. & Vincent, J. (1995) . A video-tape peer/self modeling program to increase community involvement. Child & Family Behavior Therapy, 17(3), 1-11.
- Kelly, J.A., Wildman, B.G., & Berler, E.S. (1980). Small group behavioral training to improve the job interview skills repertoire of mildly retarded adolescents. Journal of Applied Behavior Analysis, 13, 461-471.
- McNeil, B.J. & Nelson, K.R. (1991). Meta-analysis of interactive video instruction: A 10 year review of achievement effects. Journal of Computer-Based Instruction, 18(1), 1-6.
- Morgan, R.L. & Salzberg, C.L. (1992). Effects of video-assisted training on employment-related social skills of adults with severe mental retardation. Journal of Applied Behavior Analysis, 25, 365-383.
- Robertson, H.A. & Biederman, G.B. (1989). Modeling, imitation and observational learning in remediation experimentation 1979-1988: An analysis of the validity of research designs and outcomes. Canadian Journal of Behavioral Science, 21, 174-197.
- Seiz, R. C. (1982). Pygmalion: Adrift at sea. Journal of Applied Behavioral Science, 18, 127-128.
- Shapiro, E.S., Eichman, M.J., Body, J.M., & Zuber, A.M. (May 1987). Generalization effects of a taped-word intervention on reading. Paper presented at the Association of Behavior Analysis, Nashville, TN.
- Shapiro, E.S. & McCurdy, B.L. (1989). Effects of a taped-words treatment on reading proficiency. Exceptional Children, 55(4), 321-325.
- Shelton, B., Gast, D.L., Wolery, M., & Winterling, V. (1991). The role of small group instruction in facilitating observational and incidental learning. Language, Speech, and Hearing Services in School, 22, 123-133.
- Shrout, P.E., & Fleiss, J.L. (1979). Interclass correlations: Uses in assessing rater reliability. Psychological Bulletin, 86, 420-428.
- Skinner, C.H., Adamson, K.L., Woodward, J.R., Jackson, Jr., R.R., Atchison, L.A., & Mims, J.W. (1993) . A comparison of fast-rate, slow-rate, and silent previewing interventions on reading performance. Journal of Learning Disabilities, 26(10), 674-681.
- Smith, D.D. (1979). The improvement of children's oral reading through the use of teacher modeling. Journal of Learning Disabilities, 12, 172-175.
- Weiner, B.J. (1971). Statistical principles in experimental design (2nd ed.). New York: McGraw-Hill.
- Wolery, M., Ault, M.J., Gast, D.L., Doyle, P.M., & Griffen, A.K. (1990). Comparison of constant time delay and the system of least prompts in teaching chained tasks. Education and Training in Mental Retardation, September, 243-257.
- Wolery, M., Ault, M.J., Gast, D.L., Doyle, P.M., & Griffen, A.K. (1991). Teaching chained tasks in dyads: Acquisition of target and observational behaviors. Journal of Special Education, 25(2), 198-220.

